
How LLMs Work (Explained Without the Math)

When you type a prompt into ChatGPT and hit Enter, the model launches into a surprisingly complex process. Your words are broken into tokens, mapped into high-dimensional vectors, passed through layers of attention, feed-forward networks, residuals, and normalizations — and somehow, out comes a fluent response.
I’m not a machine learning engineer (and maybe you aren’t either), but that’s exactly the point of this series. We’ll explore LLMs in plain language — peeling back the layers step by step, focusing on the big ideas and intuition rather than heavy equations.
In this first post, we’ll trace what happens during a single request: from the moment you type your prompt to the instant the model chooses its next token.
Future posts will shift to the engineering side — how these models are scaled, optimized, and deployed in the real world. But to make sense of that, it helps to first understand the core mechanics. That’s why I’m starting here: a prerequisite deep dive into how LLMs actually work.
What is an LLM?
If you’ve used ChatGPT, Claude, Gemini, or similar tools, you’ve interacted with a Large Language Model (LLM).
Technically, an LLM is a huge neural network trained on massive amounts of text. It uses the transformer architecture and learns to perform one simple task:
Predict the next token (word or part of a word) based on the previous ones.
LLMs are incredibly general-purpose — they can translate, summarize, reason, write poetry, debug code, and more — because all of these tasks can be expressed as predicting the next token in a sequence.
How LLMs Process a Prompt (High-Level Overview)
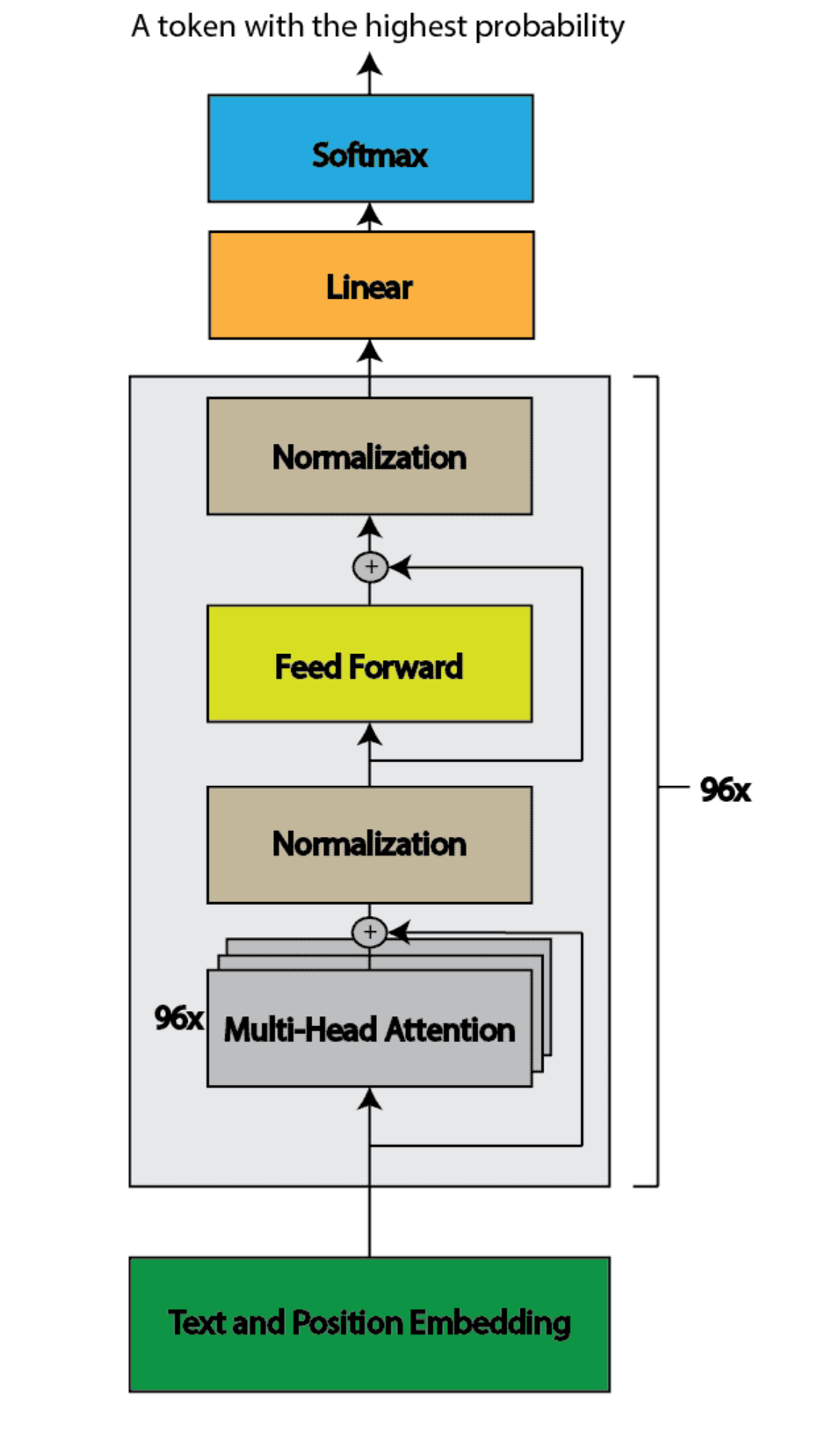
Above is a sample architecture representation of GPT 3.Here’s what happens inside the llm on a very high level:
The text is tokenized into chunks the model understands
Each token is mapped to a vector via an embedding matrix
These vectors are passed through multiple attention + MLP layers
The model uses the final vector to predict the next token
Let’s break each step down
Step 1: Tokenization
The model doesn’t work with raw text. It first breaks your input into tokens — which could be full words, parts of words, or even punctuation.
Example input:
A machine learning model
Might be tokenized as:
["A", " machine", " learning", " model"]
Each of these tokens maps to a unique token ID using the model’s internal vocabulary:
| Token | Token ID |
| ---------- | -------- |
| "A" | 101 |
| "machine" | 4923 |
| "learning" | 8011 |
| "model" | 2047 |
Step 2: Embedding — Turning Tokens Into Vectors
Each token ID is then mapped to a vector using a learned matrix called the embedding matrix. Think of this like a big lookup table.
Example (simplified to 4 dimensions):
| Token | Token ID | Embedding Vector |
| ---------- | -------- | ------------------------ |
| "A" | 101 | [0.1, -0.2, 0.05, 0.3] |
| "machine" | 4923 | [-0.3, 0.7, 0.2, -0.1] |
| "learning" | 8011 | [0.8, -0.5, 0.4, 0.6] |
| "model" | 2047 | [0.6, 0.1, -0.3, 0.9] |
At this point, each word is just a vector — but these vectors don't yet understand context. The vector for “model” is the same whether you’re talking about fashion model or machine learning model.
So how does the model figure out what kind of “model” we mean?
Step 3: Attention block — Adding Context
The answer is the attention mechanism in the transformer architecture. Take these two similar-looking prompts:
"A machine learning model"
"A fashion model"
In both, the word “model” is the same token ID with the same embedding vector. But clearly, it means something different in each case.
This is where self-attention comes in.
Self-attention lets each token attend to other tokens in the sequence to gather context. It transforms each token's vector into a context-aware representation — so "model" can carry a different meaning depending on what came before it.
How does attention work?
For each token vector, we compute three new matrices (Q,K,V):

Each token's embedding is transformed into these three vectors using trained weight matrices:
Q = Embedding × W_q
K = Embedding × W_k
V = Embedding × W_v
The weight matrices (W_q, W_k, W_v) are learned during training through backpropagation,
Let’s Walk Through “A machine learning model”
Step 1: Tokenization
Tokens: ["A", "machine", "learning", "model"]
Each token becomes an embedding vector (say 512 dimensions). Let’s say this is the embedding for “model”:
model_embedding = [0.6, 0.1, -0.3, 0.9, ...]
Step 2: Generate Q, K, V for “model”
model_query = model_embedding × W_q = [0.2, 0.7, -0.1, ...]
model_key = model_embedding × W_k = [0.6, -0.2, 0.3, ...]
model_value = model_embedding × W_v = [-0.1, 0.5, 0.4, ...]
Similarly, we compute Q, K, V vectors for all other tokens: "A", "machine", and "learning".
Step 3: Calculating Attention Scores
The model now compares the Query vector of “model” with the Key vectors of all other tokens:
Attention("model" → "machine") = model_query · machine_key = 0.88
Attention("model" → "learning") = model_query · learning_key = 0.93
Attention("model" → "A") = model_query · A_key = 0.10
This tells the model that “learning” and “machine” are strongly relevant to “model”, while “A” is not as important.
Step 4: Building Contextual Meaning
The final representation for “model” is now built by taking a weighted sum of all Value vectors, based on these attention scores:
contextualized_model =
0.93 × learning_value +
0.88 × machine_value +
0.10 × A_value +
...
This updated vector now encodes that “model” refers to a machine learning concept, not a person.
Comparing With: “A fashion model”
If the input were:
Tokens: ["A", "fashion", "model"]
Now the attention scores might look like:
Attention("model" → "fashion") = 0.97
Attention("model" → "A") = 0.12
This causes “model” to pick up a very different contextual meaning, now referring to a person.
Attention Formula
All of this happens via this one equation:
Attention(Q, K, V) = softmax(Q × Kᵀ / √d_k) × V
Where:
Q × Kᵀ: Computes similarity between tokens√d_k: Normalizes to prevent large dot productssoftmax: Converts scores into probabilities× V: Computes the weighted sum
This whole process is repeated in multiple attention heads — each learning different aspects of language — and stacked across dozens or hundreds of layers.
Step 4: MLP + Layer Norm + Residuals
The Feed-Forward Network (FFN): Thinking in Bigger Space
After attention, each token goes through a feed-forward network — the same small neural network applied independently to every token.
The FFN temporarily expands the token’s vector (often to about 4× its original size, e.g., 12,288 → 49,152 dimensions), applies a non-linear activation such as ReLU or GeLU, and then compresses it back down.
Expanding gives the model room to discover richer patterns.
Compressing makes sure the output stays manageable for the next layer.
This step helps the model turn context into more abstract and useful features.
Residual Connections: Keeping the Original Signal
Instead of throwing away the original input, the model adds it back to the transformed output:
output = FFN(x) + x
Here:
x is the input vector to the layer (the token’s current representation).
At the start of the model, x comes from the embedding layer (a vector representing the word/piece of text).
In later layers, x is the already-processed representation after going through previous attention + FFN blocks.
FFN(x) is the transformed version of that vector, after passing through the feed-forward network.
By combining both, the model:
Preserves the original information (so nothing important is lost).
Adds a refined version (so the representation becomes richer at each layer).
Helps gradients flow backwards during training, preventing them from vanishing.
That’s why GPT-3 can safely stack 96 layers: each layer improves on what came before without overwriting it.
Layer Normalization: Staying Stable
Every layer also applies layer normalization, which keeps values from blowing up or shrinking too much. It rescales activations so training stays stable.
Modern architectures like GPT-3 use pre-layer norm: normalization happens before the FFN or attention block. This simple shift improves gradient flow and makes very deep models easier to train.
Why All Three Matter
Together, these parts make stacking dozens of layers possible:
FFN: transforms each token into richer representations.
Residuals: preserve and carry forward useful signals.
Layer norm: keeps training balanced and stable.
This design lets later layers go beyond grammar and syntax, moving toward deeper reasoning and abstract understanding.
Step 5: Predicting the Next Token
After all layers are done, the LLM now has a final hidden vector for each position in the prompt.
The vector for the last token is used to predict the next token.
How?
The final vector is passed through a matrix (called the unembedding matrix — often tied to the input embedding matrix).
This produces a vector of logits — one score per vocabulary token (e.g. 50,000+ tokens).
A softmax turns these logits into probabilities.
The model samples the next token using a decoding strategy:
Greedy decoding: Always selects the highest probability token
Top-k sampling: Selects from the k most likely tokens
Top-p sampling: Selects from tokens whose cumulative probability exceeds threshold p
The predicted token is then added to the prompt, and the process repeats — one token at a time.
Recap: How LLMs Predict Tokens
Input Prompt → User types text
Tokenization → Break into tokens
Embedding Lookup → Tokens → Vectors
Attention Layers → Contextualize each token
MLPs → Non-linear transformations
Final Hidden State → Represents all prior context
Unembedding + Softmax → Predict next token
What’s Next?
In the next post, we’ll shift from how LLMs work to how to make them work faster and at scale. We’ll dive into:
Optimizing inference for different workloads — from long inputs to long outputs.
Practical speed-up techniques like batching, KV caching, and speculative decoding.
Infrastructure for online vs. offline inference — and how frameworks like vLLM make deployment easier.
I’ll also add more visuals and diagrams to make the concepts even more intuitive.
Thanks for reading! 🙏 I hope you found this post useful, and I’d love to hear your thoughts or feedback — it’ll help me shape the rest of this series.